As highlighted above, the editor, Diane Guerrero
(DG), at janelead.org implies the use of OCR technology on her alleged copies of JL's
original manuscripts, which she claims to have used to produce the electronic files
from which she began her edited, derivative renditions of Jane Lead's works.
When challenged by PTW, the
editor refused to provide ANY proof that she even owned OCR software, or ANY samples of
OCR output from ANY of the documents that had recently appeared at janelead.org which, we
now believe, have been built upon the copyrighted, electronic, source files stolen from
PTW.
|
Read on...about why typical OCR software
simply doesn't work on the Jane Lead originals... |
First, take a look at and
attempt to read a few lines of a sample copy of an original printed page from the 17th
century showing the printing-style and character-set that were typically used in the
authentic originals published by Jane Lead back in the late 1600's.
Notice the unusual rendering of the character, "s", which looks different
depending on where it appears within a word. This sample (shown below) is actually a
fairly "clean" copy from which to work.

PasstheWord (PTW) determined
early-on in their labors that modern OCR technology does NOT sort out this printing-style
very well... and we'll show you why in two examples. In the experience of PTW,
many of the originals from which copies were preserved in the past (either on microfilm or
otherwise) are not as clear as the above sample.
|
|
This is a xerographic
reproduction of more typical page from an original book published by Jane Lead.
Notice the ink smudging that is prevalent.

|
|
Now here is an actual OCR scan of the left page
of the above text (done at PTW for the purpose of this review), to show an example of what
the OCR'd, MSWord output (that is produced by the OCR software) looks like...
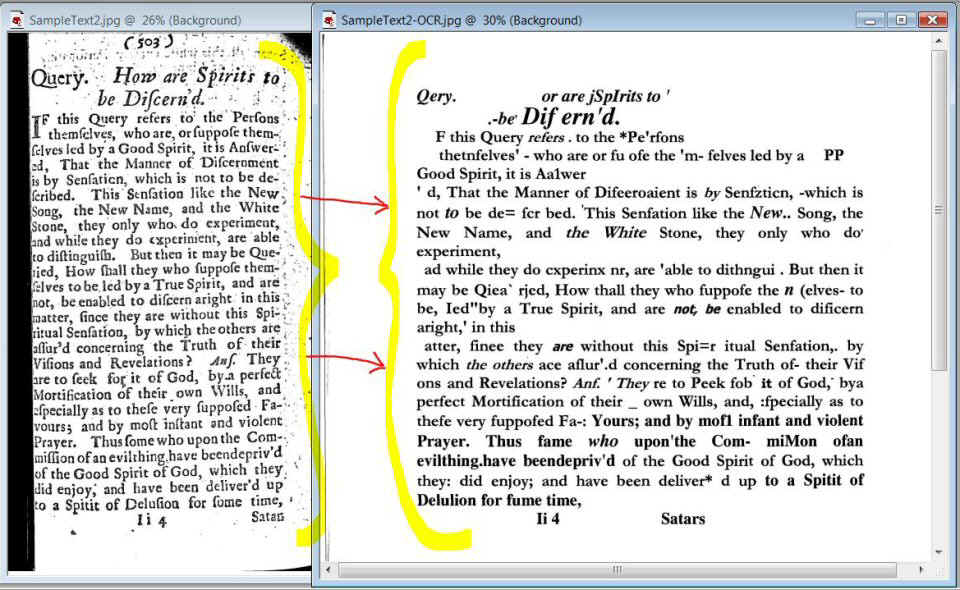
Original source page is
on the left — Output (as an MS
Word .doc file) from OCR software is on the right...
Would any of you want to
spend the time that would be required to clean up this mess (shown on the right)
in your word processor so that it matches the exact text from the source page on the
left?
It would obviously take far
less time to type the page, character by character, which is what the volunteers at
PasstheWORD chose to do, when they undertook the long process of transcribing the twenty
original manuscripts of JL's works, which have been on-line at passtheword.org for over 12
years. This is why DG's scanning claim raised a "red flag" for those at
PTW.
|
|
Here is a final page sample
— this time of an aged, wrinkled and weathered page, which had been microfilmed and
preserved by faithful hands sometime in the past...

|
Below is an attempt to
OCR this same page (done at PTW for the purpose of this review) ...not only does the
software fail to recognize the continuity of the text at the page wrinkles, but the output
is an incoherent mixture of garbled characters of varying sizes and font styles!
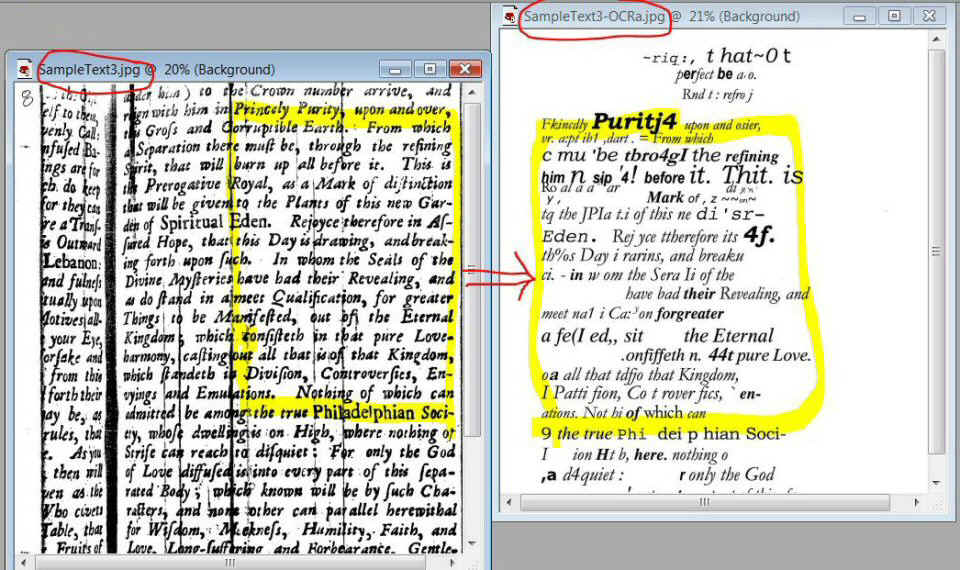
So as a result of the OCR
scan, all you have is the output of bits and pieces of the wrinkled page which would have
to be reconciled with the other fragments; all the word-scanning errors would need
to be found and corrected before you could put the sentences back together so that you
would have a rendering in electronic form of the text of the entire sample-page put back
together with the sentences in their proper order. Please take a close look
at this, up close, and envision the enormity of the task...

Again, we submit, that when
faced with the task of producing an accurate transcription of this page, an honest person
would choose to type it directly rather than to waste time with typical OCR
Software...that is, unless it had already been transcribed and you could take a big
shortcut...just help yourself to a copy, and then tell everyone that you had simply
"scanned the original".
The
Details of DG's alleged Methodology
In February of 2009, when PTW
challenged DG's scanning claim, she refused to provide any proof of her methodology.
If there was one, why didn't she simply supply it? If DG had nothing to hide, why
not openly, obediently and honestly answer the concerns that were put to her?
Instead, she stopped communicating directly with PTW in March of 2009.
By August of 2009, however,
she had posted on-line at janelead.org, an inventive detailed explanation of how
she supposedly accomplished the "scanning" of originals into electronic
form.
At the beginning of that
document DG shared her experience with trying to type the text: "I typed all day long for two weeks and ended up with a severe case of
tendonitis in my right thumb and wrist" which disability, we are supposed to
believe, led her to invent her method for scanning all the manuscript copies and
convert them into text (see excerpts below).
Below are screen captures
from her on-line document. Please read Diane Guerrero's explanation with a spirit of
discernment.
Excerpts from Diane Guerrero's
2009 On-Line Document Describing her Scanning Method



|
Seriously?? This is the
elaborate, head-spinning description of the editor's lengthy process which she allegedly
used to scan each original page into electronic text. DG's imaginative process
employs an incredible, 100-step macro and many manual passes by the editor on each and
every word, of each and every sentence, of each and every paragraph, of each and every
scanned page — is this story really believable? ... or is it just an attempt to cover
up her theft which PTW had exposed.
When you consider that there
are thousands of JL's original pages to convert into electronic form, wouldn't you choose
to transcribe them one word at a time rather than attempt to use typical OCR technology?
When PTW experimented with it, the use of OCR was counterproductive; it took
far longer to achieve an accurate electronic rendering of the text with OCR software than
it did by simply typing the text!
 UPDATE: It may be of interest to know that Diane Guerrero's
description (shown above) of her methodology first appeared at janelead.org in
August of 2009, but it had disappeared by April of 2010 for her own reasons, but her
website continued to say that all manuscripts were scanned by her and converted into
text. By the 13th of May, 2012, her home-page was saying that she had personally
scanned or typed all manuscript copies into text. Later that month,
when she changed to a commercial format for her website [where there were no more free
downloads or promised free booklets, but everything was for sale], the commercial website
still repeated her new claim that she had personally scanned or typed all
the manuscript copies into text. It wasn't long before she changed back to offering
free downloads after we pointed out her broken promises, but the promised free booklet
offer never reappeared. In 2014 she was back to saying that all of the JL microfilm
copies had been scanned and converted into text! Hmmmm.
UPDATE: It may be of interest to know that Diane Guerrero's
description (shown above) of her methodology first appeared at janelead.org in
August of 2009, but it had disappeared by April of 2010 for her own reasons, but her
website continued to say that all manuscripts were scanned by her and converted into
text. By the 13th of May, 2012, her home-page was saying that she had personally
scanned or typed all manuscript copies into text. Later that month,
when she changed to a commercial format for her website [where there were no more free
downloads or promised free booklets, but everything was for sale], the commercial website
still repeated her new claim that she had personally scanned or typed all
the manuscript copies into text. It wasn't long before she changed back to offering
free downloads after we pointed out her broken promises, but the promised free booklet
offer never reappeared. In 2014 she was back to saying that all of the JL microfilm
copies had been scanned and converted into text! Hmmmm.
|
After reviewing this report,
what does your heart tell you about the validity of DG's scanning claim, and her
truthfulness as the editor of these illegal SDV editions? Is her word to be
trusted?
Beloved Reader, beware of what
you find at janelead.org... and also of DG's added deception (from
Summer, 2012 through late 2014), an exact duplicate website, called spiritsday.org.
The documents to be found on
both of DG's websites have been altered, and they cannot be counted on as being true to
the meaning of Jane Lead's authentic originals.
Links to the other evidentiary reports can be
found at the bottom of the Fair Warning Reports Page.
|
| Back to:
The Fair
Warning Reports Page |
| Back to: Index of Jane Lead Manuscripts |